

SWE-Lancer是什么?
SWE-Lancer 是 OpenAI 开源的一个全新评估大模型代码能力的测试基准,通过端到端测试来模拟真实的开发任务,旨在更全面地评估大语言模型在软件工程任务中的表现,尤其是处理复杂、全栈任务的能力。其测试数据集包含 1488 个来自 Upwork 平台上 Expensify 开源仓库的真实开发任务,涵盖独立开发和管理任务,总价值高达 100 万美元。
SWE-Lancer的主要特点
- 端到端测试:SWE-Lancer通过模拟完整的用户交互流程,测试不仅验证单个功能的实现,还确保整个开发任务的连贯性和正确性。这种方式更加贴近现实中的软件开发场景。
- 真实开发任务:SWE-Lancer包含来自Upwork平台的1488个开发任务,这些任务涉及修复漏洞、实现功能、选择最佳解决方案等,分为独立开发任务和软件工程管理任务两类。
- 高价值任务:数据集总价值达到 100万美元,任务内容涵盖了高难度、高价值的软件工程挑战,旨在测试大模型是否能够解决复杂的实际问题。
- 全面评估:测试不仅评估模型解决单个问题的能力,还考察模型如何应对复杂的系统交互、数据库操作等多方面挑战,提供更为全面的能力评估。
- 现实性强:SWE-Lancer通过模拟真实开发场景和任务,使得模型测试更具实际意义,评估结果能够真实反映大模型在软件开发中的应用潜力与局限性。
SWE-Lancer的数据集
SWE-Lancer数据集一共包含1488个来自Upwork平台上Expensify开源库的真实软件开发任务,一共分为独立贡献者和软件工程管理任务两大类。
独立开发任务一共有764个,价值414,775美元,主要模拟个体软件工程师的职责,例如,实现功能、修复漏洞等。在这类任务中,模型会得到问题文本描述涵盖重现步骤、期望行为、问题修复前的代码库检查点以及修复目标。
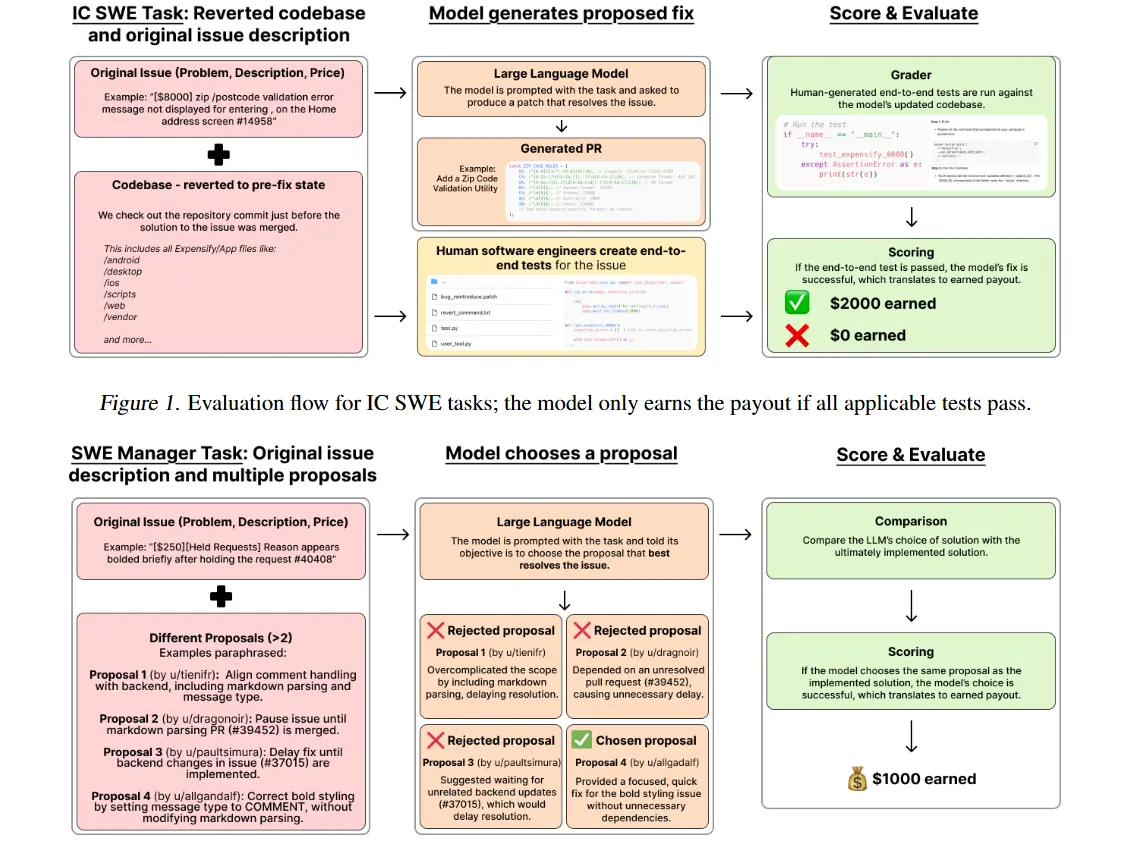
软件管理任务,有724个,价值585,225美元。模型在此类任务中扮演软件工程经理的角色,需要从多个解决任务的提案中挑选最佳方案。例如,在一个关于在iOS上实现图像粘贴功能的任务中,模型要从不同提案里选择最适宜的方案。
首批SWE-Lancer测试结果
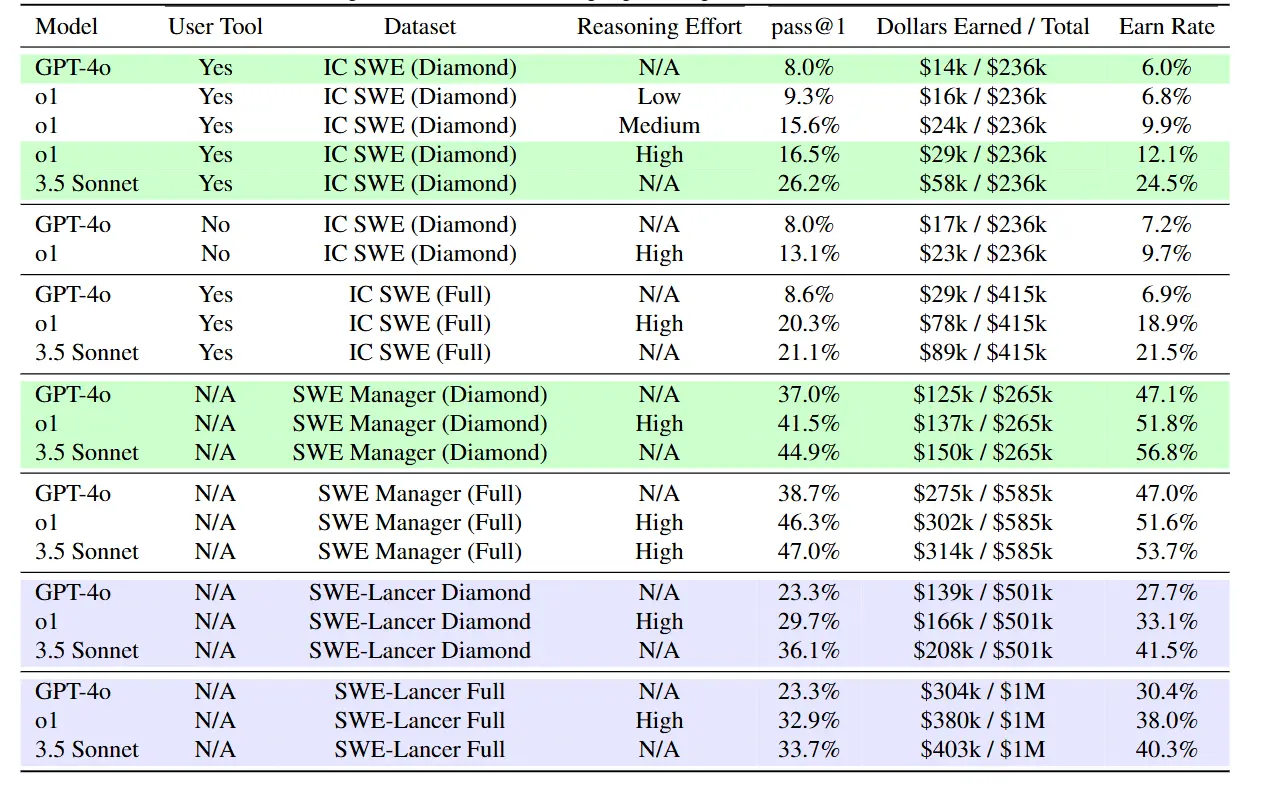
OpenAI使用了GPT-4o、o1和Claude3.5Sonnet在SWE-Lancer进行了测试,结果显示:
- 在独立开发任务中,表现最好的 Claude 3.5 Sonnet 的通过率仅为 26.2%,而 GPT-4o 的通过率仅为 8%。
- 在软件工程管理任务中,Claude 3.5 Sonnet 的通过率为 44.9%,GPT-4o 的通过率为 37.0%。
- 在高价值、复杂任务中,模型的通过率普遍低于 30%,表明模型在处理复杂任务时仍比人类差很多。
如何使用SWE-Lancer?
SWE-Lancer的开源资源如下:
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...


