
Kimi-VL是什么?
Kimi-VL 是由北京月之暗面公司推出的一款开源视觉语言模型(VLM),具备原生分辨率图像理解、多模态推理和128K长上下文处理能力。其基于轻量化的 MoE 架构语言模型 Moonlight 和自研视觉编码器 MoonViT,可处理图像、视频、图文混合、屏幕快照等多种多模态输入场景,支持复杂任务中的高效视觉感知与推理。模型性能在多个 VLM 基准上表现优越,兼具推理深度与执行效率。

Kimi-VL 的功能特性
- 原生多模态输入支持:可处理图像、视频、图文长文档、屏幕快照等丰富视觉语言组合。
- 128K 长上下文推理:具备大上下文窗口,在长视频理解与长文档摘要中表现优异。
- 高保真视觉感知能力:MoonViT 编码器保留图像原始分辨率,提升 OCR、细节感知与图像理解能力。
- 轻量高效的 MoE 架构:采用 16B 总参数、2.8B 激活参数的 Moonlight 模型,实现推理效率与多模态表达兼得。
- 支持长链式思维版本(Kimi-VL-Thinking):通过强化学习激活思维链推理(Long CoT),在复杂任务中效果超越部分超大模型。
- 完整开源、易于部署:模型已在 Hugging Face 与 GitHub 完全开源,支持本地运行与二次开发,适合社区研究与产品快速集成。
Kimi-VL 的模型架构
Kimi-VL 的整体架构由三大核心模块组成:原生分辨率视觉编码器 MoonViT、桥接视觉与语言的 MLP 投影模块,以及轻量高效的 MoE 架构语言模型 Moonlight。这三个部分共同构建了一个高性能、长上下文、强视觉理解能力的多模态模型。
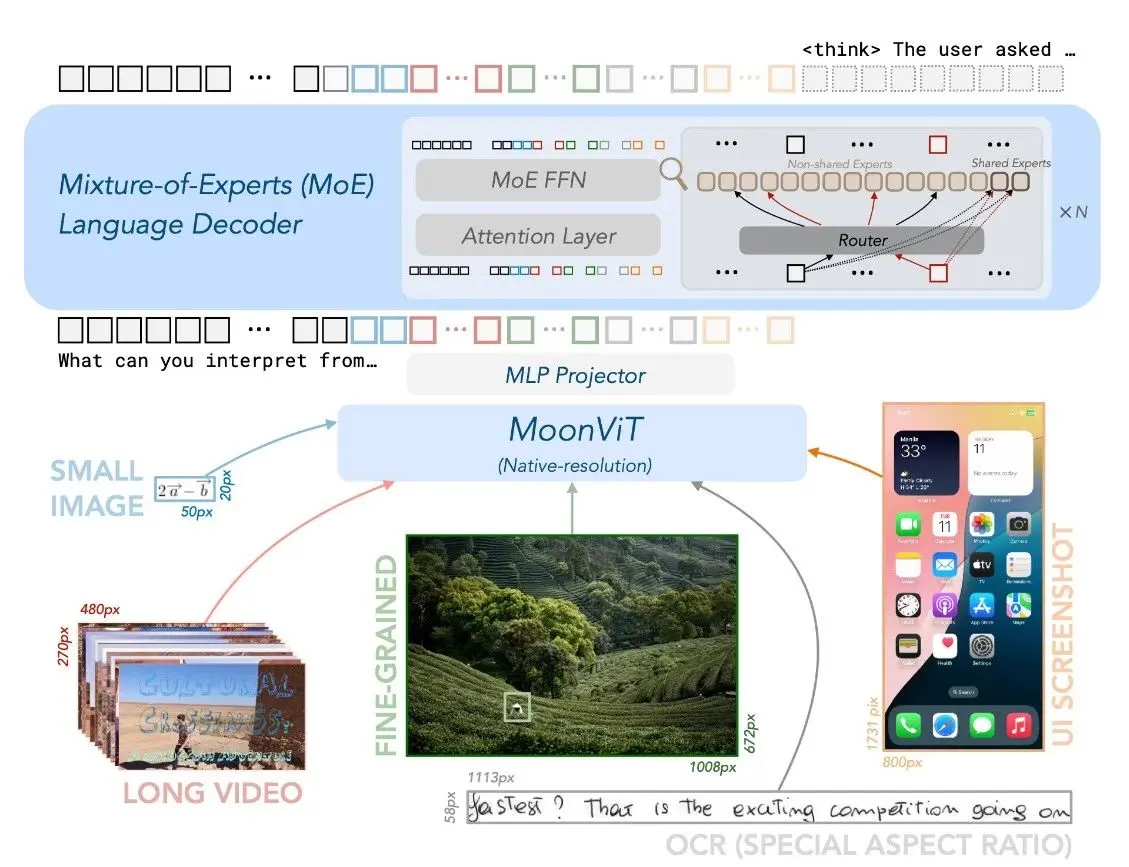
1️⃣ MoonViT:支持原生分辨率的视觉编码器
- 专为 Kimi-VL 设计,具备处理原始分辨率图像的能力,无需图像分割或拼接。
- 借鉴 NaViT 的打包方法,将图像划分为块后展平成一维序列,提升编码效率。
- 与语言模型共享 FlashAttention 支持的变长序列处理能力,保证在处理不同大小图像时训练吞吐量不受影响。
2️⃣ MLP Projector:视觉与语言模态的桥接层
- 采用两层 MLP 模块连接 MoonViT 与语言模型,实现特征维度对齐。
- 首先通过 像素重排(Pixel Shuffle) 对视觉特征进行 2×2 下采样,并扩展通道维度。
- 再通过 MLP 将下采样后的特征投影到与语言模型输入一致的嵌入维度,确保多模态信息无损融合。
3️⃣ Moonlight:自研 MoE 架构语言模型
- 总参数量 16B,有效激活参数 2.8B,采用混合专家(MoE)机制提升推理效率。
- 初始化自 Moonlight 预训练中间 checkpoint,已处理 5.2T 纯文本数据、支持 8K 上下文。
- 在多模态阶段进一步使用 2.3T token 的图文混合数据进行训练,显著增强模型跨模态对齐与长文本理解能力。
Kimi-VL 的适用场景
- 多模态问答系统开发:支持图文混合、视频帧、屏幕截图等多模态输入,适用于构建具备视觉理解能力的 AI 助手或教育问答系统。
- 长文档和长视频理解:凭借 128K 上下文窗口能力,可精准提取、总结和推理超长内容,适用于合同审阅、视频摘要、研究报告分析等任务。
- OCR 与图像细节分析:在高分辨率图像、表格、票据等场景中表现出色,适合金融文档识别、表单解析、图像标注等任务。
- 多步骤视觉推理与数学理解:结合图像信息与链式思维能力,可用于图形题、多图推理、数学可视化问题等教育或科学研究类场景。
- 智能体控制与屏幕交互:在支持高分辨率屏幕截图解析的基础上,适合接入多模态 Agent 系统,执行跨应用控制、UI 元素识别等任务。
如何使用 Kimi-VL
Kimi-VL 为开源模型,支持 Hugging Face 上直接加载模型权重,也支持 GitHub 本地部署。可通过推理 API 或集成进多模态任务链中运行。Kimi-VL-Thinking 版本支持推理更深的思维链任务,适用于逻辑推理与多步骤复杂问答。
- ArXiv 论文:https://arxiv.org/abs/2504.07491v1
- Github 代码:https://github.com/MoonshotAI/Kimi-VL
- Hugging Face 模型下载:https://huggingface.co/collections/moonshotai/kimi-vl-a3b-67f67b6ac91d3b03d382dd85
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...


